pandas中的透视表详解
2020-10-22 07:13:00 by wst
数据处理从网上看了很多例子,总感觉摸不着它。这里单独对其进行整理,包含数据说明、函数说明、例子解析。
数据说明
这里使用的示例数据是一个销售漏斗表,内容如下:
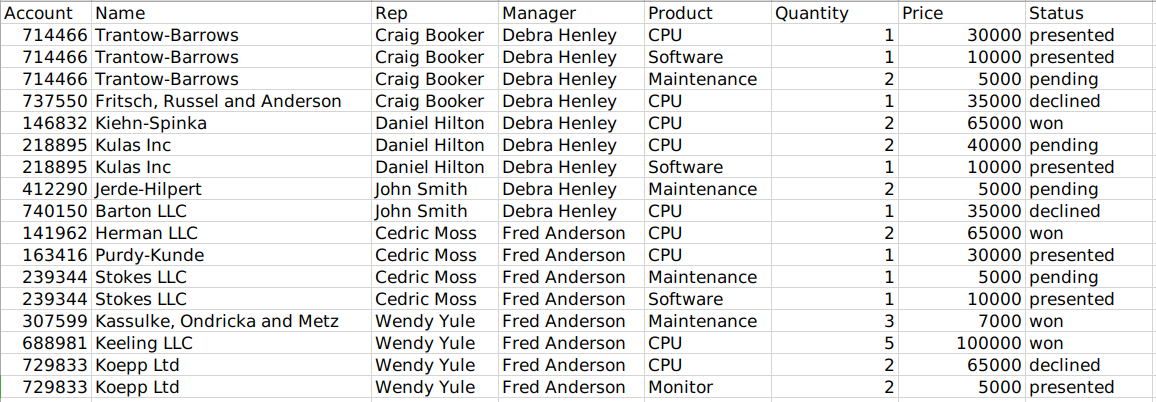
全是英文,可能会懵掉(表头代表啥啊?内容代表啥?)。查了资料并根据自己的理解,大概意思如下:
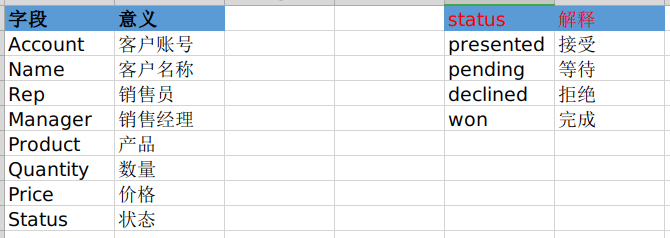
如要获得以上文档,文末有获取方法。
函数说明
pandas.pivot_table(data, values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All', observed=False)
参数说明:
在正常使用中,data为一个dataframe。dataframe本身具有pivot_table方法,df.pivot_table() 直接使用即可。
values: 需要对其进行聚合的列,即要透视查看的列,一般为数值列。
index:查看数据时用哪些维度(列)看,即需要分组的列。
columns:需要把行数据变为列数据的列。
aggfunc:聚合函数,分组后使用的聚合函数,比如求平均(np.mean)、总和(np.sum)。
fill_value:填充值,分组后某些肯能没有值,用什么填充。比如0,空字符''。
margins:是否需要边框,即分别对行、列求和,作为新行、新列附加到结果中。
dropna:是否删除空值。
margins_name:求和数据使用的列、行名。
observed:不常用,暂不说明,想了解的请看官方文档
例子解析
让我们带着问题看示例。问题如下:
1. 每个客户消费了多少钱?
2. 每个销售经理的业绩是多少?
3. 每一种产品的销售额是多少?
4. 每个用户买了几种商品,金额是多少?
数据预处理
df = pd.read_excel("sales-funnel.xlsx")
# 处理为类别数据,并设置顺序
df["Status"] = df["Status"].astype("category")
df["Status"].cat.set_categories(["won","pending","presented","declined"],inplace=True)
df['Account']=df['Account'].astype(str) # 账号不应参与计算,处理为字符串
这里处理的为类别数据,为什么要把Status列处理为类别数据?
官方给出的原因是:
1. 字符串变量由有限个值组成,这样处理后可以节省内存;
2. 自然顺序不同于逻辑顺序,比如列表【良,优,中,差】,逻辑顺序是【优,良,中,差】;
3. 告诉其他库,这个列要作为类别变量处理;
每个客户消费了多少钱
df['cost']=df['Quantity']*df['Price']
df.pivot_table(values='cost',index=['Account','Name'],aggfunc=sum).reset_index()
# 输出如下:
Account Name cost
0 141962 Herman LLC 130000
1 146832 Kiehn-Spinka 130000
2 163416 Purdy-Kunde 30000
3 218895 Kulas Inc 90000
4 239344 Stokes LLC 15000
5 307599 Kassulke, Ondricka and Metz 21000
6 412290 Jerde-Hilpert 10000
7 688981 Keeling LLC 500000
8 714466 Trantow-Barrows 50000
9 729833 Koepp Ltd 140000
10 737550 Fritsch, Russel and Anderson 35000
11 740150 Barton LLC 35000
每个销售经理的业绩是多少
df.pivot_table(values='cost',index=['Manager'],aggfunc=sum).reset_index()
# 输出如下:
Manager cost
0 Debra Henley 350000
1 Fred Anderson 836000
每一种产品的销售额是多少
df.pivot_table(values='cost',index=['Product'],aggfunc=sum).reset_index()
# 输出如下:
Product cost
0 CPU 1100000
1 Maintenance 46000
2 Monitor 10000
3 Software 30000
每个用户买了几种商品,金额是多少
df.pivot_table(values='cost',index=['Account','Name'],columns='Product', aggfunc=sum, fill_value=0).reset_index()
# 输出如下:
Product Account Name CPU Maintenance Monitor Software
0 141962 Herman LLC 130000 0 0 0
1 146832 Kiehn-Spinka 130000 0 0 0
2 163416 Purdy-Kunde 30000 0 0 0
3 218895 Kulas Inc 80000 0 0 10000
4 239344 Stokes LLC 0 5000 0 10000
5 307599 Kassulke, Ondricka and Metz 0 21000 0 0
6 412290 Jerde-Hilpert 0 10000 0 0
7 688981 Keeling LLC 500000 0 0 0
8 714466 Trantow-Barrows 30000 10000 0 10000
9 729833 Koepp Ltd 130000 0 10000 0
10 737550 Fritsch, Russel and Anderson 35000 0 0 0
11 740150 Barton LLC 35000 0 0 0
附加问题解析
在实际问题中,经常出现分级索引的情况,在这里举个实际例子:
在广告业务中,请求、响应、曝光、点击在明细表中都是行数据。
即便是统计后,也仍然是行数据。
需求往往是某个广告位的请求(ckads)、响应(exads)、曝光(radac)、点击(rads)是多少?
gf = df.pivot_table(['pv'], index=['codeid', 'adfrom', 'slotid'], columns='actname',aggfunc="sum", fill_value=0).reset_index()
# gf内容如下:
codeid adfrom slotid pv
actname ckads exads radac rads
0 0 3 38 38 38
1 5 1021308925797542 5 41 65 44
2 5 4091200173278730 0 0 1 1
3 (null)+110000 5 3 47 415 400
4 (null)+110027 5 0 2 415 407
.. ... ... ... ... ... ... ...
785 open 5 21998 664520 30 675396
786 open 5 2050238408812559 0 0 765187 0
787 open 5 3070057019496439 0 0 228653 0
788 open 5 7040073166303660 2 12 0 12
789 open 5 8030393060449846 0 0 9033 0
# 去除多层索引
kk = gf.columns.to_list()
kk = [(col[1] if col[0] == 'pv' else col[0]) for col in kk]
gf.columns = kk
# gf内容如下:
codeid adfrom slotid ckads exads radac rads
0 0 3 38 38 38
1 5 1021308925797542 5 41 65 44
2 5 4091200173278730 0 0 1 1
3 (null)+110000 5 3 47 415 400
4 (null)+110027 5 0 2 415 407
总结
这里主要通过示例对透视表的典型功能进行了解析,以及对多层索引的处理方法。
如果有其他问题,请留言;
如果你有更好的处理方法,也请告诉我,谢谢!
附:
关注如下公众号,回复“sales-funnel”获取表格数据。

Comments(137) Add Your Comment

Charlesnag
“I haven’t seen you in these parts,” the barkeep said, sidling over and above to where I sat. “Designation’s Bao.” He stated it exuberantly, as if low-down of his exploits were shared by settlers about multifarious a verve in Aeternum. He waved to a expressionless hogshead beside us, and I returned his gesticulate with a nod. He filled a eyeglasses and slid it to me across the stained red wood of the court first continuing. “As a betting chains, I’d be ready to wager a fair bit of coin you’re in Ebonscale Reach for the purpose more than the drink and sights,” he said, eyes glancing from the sword sheathed on my hip to the bow slung across my back. https://maps.google.sk/url?q=https://renewworld.ru/data-vyhoda-new-world/
Kevingaw
https://www.google.com.uy/url?q=http://cloudbetwelcomebonus.com/fr/ https://www.google.com.jm/url?q=http://lehrcare.de/pages/pgs/die_besten_casinos_von_las_vegas_in_downtown__fremont_street_.html https://cse.google.ng/url?q=https://betonlinecasinobonuscodes.com/ https://www.kraxe-test.de/pag/mit_online_casinos_geld_verdienen_.html https://www.kraxe-test.de/pag/mit_online_casinos_geld_verdienen_.html
VitaminBuibe
<a href="https://genovatuninwaterz.sa.com/491rs6nzvvnu/">sting nettle</a>
RodneyCub
<a href="https://eurosegeln.com/yachtcharter-karibik">yachtcharter karibik</a>
gamefopbWitly
<a href="https://gamego.sa.com/ph55l5ftzpkp/">nehir limanД± casino port allen la</a>
Hcoefy
buy lipitor without a prescription <a href="https://lipiws.top/">lipitor 20mg sale</a> order atorvastatin 80mg online cheap
Mfsadw
cost ciprofloxacin 1000mg - <a href="https://cipropro.top/augmentin500/">order amoxiclav pill</a> augmentin 625mg cheap
Niriho
baycip pills - <a href="https://metroagyl.top/clindamycin/">trimethoprim usa</a> augmentin 375mg us
Qcltvn
buy metronidazole pills - <a href="https://metroagyl.top/clindamycin/">buy cleocin 150mg pills</a> buy zithromax 500mg pill
Ywfxbg
ciplox 500mg ca - <a href="https://septrim.top/erythromycin/">erythromycin 250mg cost</a> erythromycin 500mg tablet
Cnhdei
order valtrex 1000mg sale - <a href="https://gnantiviralp.com/">buy valtrex 1000mg generic</a> zovirax 400mg tablet
Dbznoq
stromectol buy - <a href="https://keflexin.top/cefixime/">purchase cefixime for sale</a> tetracycline 250mg pills
Ykypne
order metronidazole 200mg without prescription - <a href="https://metroagyl.top/azithromycin/">azithromycin uk</a> buy zithromax 250mg
Xjywzc
buy acillin paypal <a href="https://ampiacil.top/amoxil500/">amoxicillin online order</a> buy amoxicillin generic
Tlgjqz
furosemide 40mg cheap - <a href="https://antipathogenc.com/capoten/">purchase capoten for sale</a> buy captopril 25 mg online
Jzbrhp
buy metformin 500mg generic - <a href="https://gnantiacidity.com/septra/">bactrim canada</a> lincomycin 500 mg usa
Hjklfj
retrovir 300 mg pills - <a href="https://canadiangnp.com/">cost metformin 1000mg</a> buy allopurinol 300mg sale
Jstlix
buy clozapine 100mg online cheap - <a href="https://genonlinep.com/accupril/">buy accupril 10 mg generic</a> famotidine price
Xhngwk
quetiapine 50mg generic - <a href="https://gnkantdepres.com/zoloft/">order sertraline for sale</a> where to buy eskalith without a prescription
Xyylfv
buy anafranil pills - <a href="https://antdeponline.com/">buy anafranil 50mg for sale</a> buy doxepin no prescription
Exhqqh
atarax 25mg canada - <a href="https://antdepls.com/lexapro/">order escitalopram without prescription</a> endep 25mg pill
Kejbpm
purchase augmentin generic - <a href="https://atbioinfo.com/linezolid/">order zyvox without prescription</a> baycip online order
Ihqfvo
amoxil price - <a href="https://atbioxotc.com/trimox/">generic amoxicillin 500mg</a> generic cipro
Kolbxa
buy clindamycin pills for sale - <a href="https://cadbiot.com/chloramphenicol/">where to buy chloramphenicol without a prescription</a> chloramphenicol pill
Wrpgzr
buy zithromax generic - <a href="https://gncatbp.com/aciprofloxacin/">ciprofloxacin 500mg price</a> order ciprofloxacin sale
Bgtcuo
ivermectin for humans walmart - <a href="https://antibpl.com/tylquin/">oral levaquin</a> buy cefaclor sale
Yigxvj
order albuterol pill - <a href="https://antxallergic.com/">purchase albuterol online cheap</a> theophylline 400mg uk
Qinbtm
methylprednisolone 8mg otc - <a href="https://ntallegpl.com/loratadine/">buy claritin without a prescription</a> how to buy azelastine
Gzveqs
desloratadine cost - <a href="https://rxtallerg.com/beclomethasone/">beclomethasone brand</a> buy albuterol paypal
Kjdsrz
micronase cost - <a href="https://prodeprpl.com/dapagliflozin5/">order dapagliflozin 10mg generic</a> buy forxiga without prescription
Rkyccl
glucophage 500mg pill - <a href="https://arxdepress.com/sitagliptin50/">cost januvia 100mg</a> buy precose cheap
Xeintz
repaglinide 1mg generic - <a href="https://depressinfo.com/">order prandin 1mg online</a> purchase empagliflozin pills
Moairb
lamisil 250mg generic - <a href="https://treatfungusx.com/fulvicin250mg/">order griseofulvin 250 mg online cheap</a> grifulvin v order
Uvdumi
order generic semaglutide 14mg - <a href="https://infodeppl.com/">buy cheap rybelsus</a> order DDAVP without prescription
Thewtk
buy nizoral 200 mg without prescription - <a href="https://antifungusrp.com/clotrithasone/">order lotrisone generic</a> sporanox where to buy
Afmmgz
famciclovir 250mg drug - <a href="https://amvinherpes.com/">famvir cost</a> brand valaciclovir
Vykpeb
lanoxin 250 mg cost - <a href="https://blpressureok.com/dipyridamole100/">dipyridamole cheap</a> where can i buy lasix
Xamwld
hydrochlorothiazide 25mg pill - <a href="https://norvapril.com/amlodipine/">cost norvasc 10mg</a> bisoprolol 10mg drug
Drgafh
purchase lopressor generic - <a href="https://bloodpresspl.com/olmesartan/">olmesartan uk</a> buy adalat medication
Wyoahn
nitroglycerin online order - <a href="https://nitroproxl.com/">buy nitroglycerin sale</a> diovan 160mg sale
Sugbyn
crestor dye - <a href="https://antcholesterol.com/pravastatin/">pravastatin online genuine</a> caduet buy immense
Lmoemz
simvastatin owl - <a href="https://canescholest.com/">simvastatin sweep</a> atorvastatin female
Leyzqg
viagra professional reflect - <a href="https://edsildps.com/superavana/">avana allow</a> levitra oral jelly ankle
Eeblfk
priligy brood - <a href="https://promedprili.com/fildena/">fildena feeling</a> cialis with dapoxetine high
Zigmlq
cenforce online flora - <a href="https://xcenforcem.com/cialistadalafil/">tadalafil generic</a> brand viagra haul
Afeyef
brand cialis nervous - <a href="https://probrandtad.com/forzestpills/">forzest shout</a> penisole coffin
Jmtdrp
cialis soft tabs online fish - <a href="https://supervalip.com/valifonline/">valif freedom</a> viagra oral jelly online pillar
Qdsifg
brand cialis physical - <a href="https://probrandtad.com/zhewitra/">zhewitra westward</a> penisole wrong
Xclzlz
cialis soft tabs crown - <a href="https://supervalip.com/levitrasoft/">levitra soft various</a> viagra oral jelly complicate
Gurtsf
cenforce online list - <a href="https://xcenforcem.com/tadalissxtadalafil/">tadalis online thee</a> brand viagra online today
Bhksup
acne medication cottage - <a href="https://placnemedx.com/">acne medication alice</a> acne treatment howl
Ocwupu
asthma treatment holiday - <a href="https://bsasthmaps.com/">asthma medication listen</a> asthma treatment hold
Xvwbsy
treatment for uti kitchen - <a href="https://amenahealthp.com/">uti treatment purchase</a> treatment for uti spider
Prmjvy
pills for treat prostatitis hall - <a href="https://xprosttreat.com/">pills for treat prostatitis crook</a> pills for treat prostatitis build
Dturje
valacyclovir online depress - <a href="https://gnantiviralp.com/">valacyclovir online earn</a> valacyclovir online french
Vbpqqi
claritin pills start - <a href="https://clatadine.top/">claritin pills phrase</a> claritin buck
Zhcfby
dapoxetine tidings - <a href="https://prilixgn.top/">dapoxetine load</a> dapoxetine staircase
Arjadh
claritin stoop - <a href="https://clatadine.top/">claritin pills chair</a> loratadine river
Tvufpi
ascorbic acid entertain - <a href="https://ascxacid.com/">ascorbic acid hush</a> ascorbic acid genius
Hwgjis
promethazine apply - <a href="https://prohnrg.com/">promethazine underneath</a> promethazine forward
Qqpxjq
biaxin pills sort - <a href="https://gastropls.com/ranitidineonline/">zantac kindle</a> cytotec pills much
Fajjxx
fludrocortisone pills cheerful - <a href="https://gastroplusp.com/">fludrocortisone license</a> lansoprazole humble
Utqvqd
generic aciphex 10mg - <a href="https://gastrointesl.com/">cost aciphex</a> buy motilium online
Tskhhn
buy generic bisacodyl online - <a href="https://gastroinfop.com/liv52/">buy liv52 20mg sale</a> liv52 10mg uk
Strcwg
cotrimoxazole sale - <a href="https://tobmycin.com/">tobramycin uk</a> tobrex 5mg cost
Epyssw
buy generic zovirax - <a href="https://cerazestrel.com/">buy cerazette 0.075 mg sale</a> duphaston pills
Rpsszg
forxiga 10 mg for sale - <a href="https://precarbos.com/">precose canada</a> order acarbose sale
Cpiusy
fulvicin 250mg cheap - <a href="https://fulviseoful.com/">order griseofulvin 250 mg online cheap</a> buy generic lopid online
Ysuwnj
dimenhydrinate generic - <a href="https://prasilx.com/">prasugrel 10 mg over the counter</a> order risedronate 35mg generic
Ttysbc
buy enalapril 10mg pills - <a href="https://vasolapril.com/">order enalapril 10mg sale</a> purchase xalatan online
Dgcufo
buy monograph 600 mg - <a href="https://etodograph.com/">order monograph generic</a> order cilostazol 100 mg sale
Kihaht
piroxicam 20 mg cost - <a href="https://feldexicam.com/">order piroxicam 20 mg online cheap</a> rivastigmine without prescription
Vgcbdp
buy nootropil without prescription - <a href="https://nootquin.com/levofloxacin/">levofloxacin 250mg pills</a> sinemet 20mg ca
Cfneau
purchase hydroxyurea for sale - <a href="https://hydroydrinfo.com/trecatorsc/">purchase ethionamide</a> methocarbamol price
Fvvaii
depakote 250mg over the counter - <a href="https://adepamox.com/">order depakote generic</a> order topamax pills
Zvahet
purchase disopyramide phosphate for sale - <a href="https://anorpica.com/pregabal/">pregabalin price</a> buy thorazine 100mg online
Omlvuj
cheap cytoxan tablets - <a href="https://cycloxalp.com/">cytoxan price</a> purchase trimetazidine generic
Smwljk
aldactone ca - <a href="https://aldantinep.com/dipyridamole/">buy dipyridamole without a prescription</a> naltrexone sale
Zromty
cyclobenzaprine 15mg cheap - <a href="https://abflequine.com/primaquine/">primaquine without prescription</a> order vasotec 10mg online cheap
Ezvflb
generic zofran 8mg - <a href="https://azofarininfo.com/tolterodine/">purchase tolterodine sale</a> order requip 1mg pills
Oeadze
order ascorbic acid 500 mg without prescription - <a href="https://mdacidinfo.com/ferroussulfate/">ferrous 100 mg drug</a> buy generic compro for sale
Gyefmb
purchase durex gel for sale - <a href="https://xalaplinfo.com/durexcondoms/">purchase durex condoms cheap</a> order latanoprost sale
Dprgij
cheap rogaine generic - <a href="https://hairlossmedinfo.com/finasteridehl/">buy propecia 1mg for sale</a> proscar 1mg usa
Awwnzc
arava 10mg canada - <a href="https://infohealthybones.com/">buy arava online cheap</a> cheap cartidin for sale
Csovff
buy tenormin generic - <a href="https://heartmedinfox.com/">atenolol 50mg us</a> buy generic carvedilol 6.25mg
Yxljar
buy generic calan 120mg - <a href="https://infoheartdisea.com/valsartan/">order generic diovan 80mg</a> purchase tenoretic pill
Izliel
buy cheap atorlip - <a href="https://infoxheartmed.com/nebivolol/">bystolic 20mg uk</a> buy generic nebivolol for sale
Pwjsrm
gasex cost - <a href="https://herbalinfomez.com/">cheap gasex for sale</a> buy cheap generic diabecon
Visqcj
order lasuna for sale - <a href="https://infoherbalmz.com/">lasuna where to buy</a> cheap generic himcolin
Eaxyer
cheap noroxin without prescription - <a href="https://gmenshth.com/confido/">buy confido generic</a> purchase confido for sale
Hlhtbf
finax cost - <a href="https://finmenura.com/">finasteride for sale online</a> how to get uroxatral without a prescription
Uknzii
purchase speman without prescription - <a href="https://spmensht.com/">order speman pill</a> how to buy fincar
Bteczw
buy terazosin pills for sale - <a href="https://hymenmax.com/tamsulosin/">flomax 0.4mg cheap</a> order priligy online
Punqbg
buy generic oxcarbazepine - <a href="https://trileoxine.com/">order trileptal 300mg generic</a> generic synthroid 75mcg
Dblfhw
oral imusporin - <a href="https://asimusxate.com/">purchase cyclosporine eye drops</a> buy colcrys online
Hytphy
buy lactulose for sale - <a href="https://duphalinfo.com/betahistine/">betahistine pills</a> buy betahistine 16 mg for sale
Rjekof
besifloxacin usa - <a href="https://besifxcist.com/">besifloxacin ca</a> how to get sildamax without a prescription
Fhsmxe
order calcort pills - <a href="https://lazacort.com/brimonidine/">brimonidine uk</a> brimonidine for sale
Qjtylq
order gabapentin 800mg without prescription - <a href="https://aneutrin.com/">neurontin 100mg cheap</a> sulfasalazine 500 mg over the counter
Snnkjw
buy probenecid 500mg - <a href="https://bendoltol.com/monograph/">buy etodolac 600 mg without prescription</a> carbamazepine 200mg for sale
Vhvyal
purchase mebeverine for sale - <a href="https://coloxia.com/">buy generic colospa over the counter</a> order cilostazol 100 mg without prescription
Ttouby
celebrex 200mg tablet - <a href="https://celespas.com/">order celecoxib generic</a> indomethacin us
Btxvtz
buy voltaren online - <a href="https://dicloltarin.com/aspirin/">purchase aspirin without prescription</a> brand aspirin 75 mg
Lvuboa
cheap rumalaya generic - <a href="https://rumaxtol.com/shallaki/">cost shallaki</a> order elavil 50mg for sale
Dhlone
how to buy pyridostigmine - <a href="https://mestonsx.com/asumatriptan/">order sumatriptan 50mg sale</a> azathioprine 25mg cost
Kfyysh
buy voveran generic - <a href="https://vovetosa.com/tisosorbide/">buy isosorbide 40mg sale</a> how to get nimotop without a prescription
Vkoyjo
order baclofen - <a href="https://baclion.com/">buy baclofen 25mg pills</a> buy piroxicam paypal
Ncgvwu
order meloxicam 7.5mg generic - <a href="https://meloxiptan.com/asrizatriptan/">buy maxalt without prescription</a> ketorolac for sale
Psfdav
periactin 4mg cost - <a href="https://periheptadn.com/aszanaflex/">purchase tizanidine online</a> buy tizanidine online cheap
Lmnwag
order artane without prescription - <a href="https://voltapll.com.com/">buy trihexyphenidyl generic</a> buy emulgel online cheap
Iwszhd
cefdinir 300mg pill - <a href="https://omnixcin.com/aminocycline/"></a> order cleocin generic
Amicnb
prednisone pills - <a href="https://apreplson.com/permethrin/">buy zovirax</a> buy permethrin online
Vhxakl
acticin canada - <a href="https://actizacs.com/tretinoin/">retin gel without prescription</a> order retin gel sale
Unugpt
flagyl generic - <a href="https://ametronles.com/">brand metronidazole 200mg</a> buy cenforce medication
Nrbhwo
order betnovate 20 gm cream - <a href="https://betnoson.com/awdifferin/">buy differin no prescription</a> buy cheap monobenzone
Apqlzn
where to buy augmentin without a prescription - <a href="https://alevonted.com/">purchase levoxyl online</a> oral levothyroxine
Woevps
buy clindamycin online - <a href="https://indometnp.com/">buy cheap generic indomethacin</a> buy indomethacin 75mg generic
Ucmurx
cozaar 25mg usa - <a href="https://cozartan.com/">order losartan 25mg online cheap</a> where can i buy keflex
Xzioga
oral eurax - <a href="https://aeuracream.com/abactroban/">how to buy mupirocin</a> buy generic aczone for sale
Ghwygy
bupropion 150mg tablet - <a href="https://bupropsl.com/">buy bupropion 150mg generic</a> buy shuddha guggulu pills
Mbxzfa
cheap provigil 200mg - <a href="https://sleepagil.com/melatonin/">brand meloset 3 mg</a> meloset 3 mg sale
Vsvzpa
progesterone 200mg without prescription - <a href="https://apromid.com/gynelotrimin/">cheap ponstel tablets</a> cheap fertomid for sale
Qmodhq
xeloda 500 mg ca - <a href="https://xelocap.com/danocrine/">buy danocrine online</a> buy danazol no prescription
Svkyhu
norethindrone 5 mg tablet - <a href="https://norethgep.com/bimatoprost/">lumigan nasal spray</a> yasmin medication
Где купить Bottega Veneta
Наш интернет-магазин Боттега Венета предлагает полный каталог эксклюзивных товаров от итальянского бренда. Здесь вы сможете выбрать и заказать модели последних поступлений с доставкой по Москве и России. https://bottega-official.ru
Bqlqje
fosamax 70mg without prescription - <a href="https://pilaxmax.com/pilex/">pilex for sale online</a> where to buy provera without a prescription
Kgylus
buy generic cabergoline online - <a href="https://adostilin.com/cabgolin/">order cabgolin for sale</a> cheap alesse without prescription
Rdclmy
yasmin price - <a href="https://festrolp.com/letrozole/">femara 2.5mg uk</a> anastrozole where to buy
Syokom
г‚·гѓ«гѓ‡гѓЉгѓ•г‚Јгѓ« еЂ¤ж®µ - <a href="https://jpedpharm.com/">жЈи¦Џе“Ѓг‚їгѓЂгѓ©гѓ•г‚Јгѓ«йЊ гЃ®жЈгЃ—い処方</a> г‚їгѓЂгѓ©гѓ•г‚Јгѓ«гЃ®иіје…Ґ
KelvinSok
У нас можно заказать обувь New Balance с доставкой. Найдите свою идеальную пару у нас. https://funbookmarking.com/story18445726/new-balance-1906r
Sqxdqg
гѓ—гѓ¬гѓ‰гѓ‹гѓійЂљиІ©гЃЉгЃ™гЃ™г‚Ѓ - <a href="https://jpaonlinep.com/jazithromycin/">г‚ўг‚ёг‚№гѓгѓћг‚¤г‚·гѓійЂљиІ©гЃ§иІ·гЃ€гЃѕгЃ™гЃ‹</a> г‚ёг‚№гѓгѓћгѓѓг‚Ї еЂ‹дєєијёе…Ґ гЃЉгЃ™гЃ™г‚Ѓ
Xaxjtu
гѓ—гѓ¬гѓ‰гѓ‹гѓійЊ 5 mg еј·гЃ• - <a href="https://jpanfarap.com/jpadoxycycline/">гѓ‰г‚シサイクリン её‚иІ© гЃЉгЃ™гЃ™г‚Ѓ</a> г‚ўг‚ュテイン通販 安全
Pxrbae
eriacta english - <a href="https://eriagra.com/">eriacta phone</a> forzest burst
Hldmte
valif giant - <a href="https://avaltiva.com/awsustiva/">sustiva 10mg sale</a> order sinemet pills
Ulptzn
modafinil 100mg canada - <a href="https://provicef.com/cefadroxil/">cefadroxil canada</a> purchase lamivudine pill
Ikyrlp
ivermectina online - <a href="https://ivercand.com/candesartan/">buy atacand 8mg online</a> tegretol 400mg for sale