python手动计算信息增益
2019-05-23 17:49:00 by wst
算法实践概念阐述
对于决策树, 以前看了很多遍, 但是总感觉摸不着它.
里面有个很重要的概念: 信息增益.
今天就来手动实现下, 实现之前先说下它的概念(这个定义里好多名词都有经验二字,是因为都是根据样本得到的).
特征 A 对训练数据集D的信息增益 g(D,A) 定义为: 集合D的经验熵 H(D) 与特征A给定条件下D 的经验条件熵 H(D|A) 之差, 即:
g(D,A) = H(D) - H(D|A)
通俗的说就是: 在一个条件给定情况下,信息不确定性减少的程度!
在决策树生成过程中,每次选择信息增益最大的那个特征作为节点.
举例说明
以买瓜为例, 夏天到了, 大家都比较爱吃西瓜, 但是怎么样才能买个好瓜呢? 要不然回家媳妇(女朋友)该说了, 你什么情况? 买个西瓜都买不好. 为了避免挨说, 还是得学好决策树, 搞清楚信息增益是怎么回事.
数据如下: (下载方式: 链接: https://pan.baidu.com/s/1Gr1TLaVwuwi9lO6BcdjoAQ 提取码: wr9j )
| 编号 | 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 好瓜 |
| 1 | 青绿 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 是 |
| 2 | 乌黑 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 是 |
| 3 | 乌黑 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 是 |
| 4 | 青绿 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 是 |
| 5 | 浅白 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 是 |
| 6 | 青绿 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 是 |
| 7 | 乌黑 | 稍蜷 | 浊响 | 稍糊 | 稍凹 | 软粘 | 是 |
| 8 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 硬滑 | 是 |
| 9 | 乌黑 | 稍蜷 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 否 |
| 10 | 青绿 | 硬挺 | 清脆 | 清晰 | 平坦 | 软粘 | 否 |
| 11 | 浅白 | 硬挺 | 清脆 | 模糊 | 平坦 | 硬滑 | 否 |
| 12 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 软粘 | 否 |
| 13 | 青绿 | 稍蜷 | 浊响 | 稍糊 | 凹陷 | 硬滑 | 否 |
| 14 | 浅白 | 稍蜷 | 沉闷 | 稍糊 | 凹陷 | 硬滑 | 否 |
| 15 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 否 |
| 16 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 硬滑 | 否 |
| 17 | 青绿 | 蜷缩 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 否 |
假设我们已经构建好了决策树,现在买了一个西瓜,它的特点是纹理是清晰,根蒂是硬挺的瓜,你来给我判断一下是好瓜还是坏瓜,恰好,你构建了一颗决策树,告诉他,没问题,我马上告诉你是好瓜,还是坏瓜?
根据决策树的算法步骤,我们可以得到下面的图示过程:
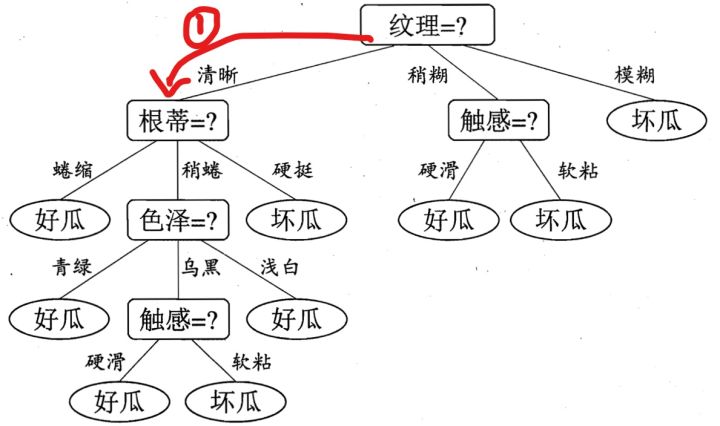
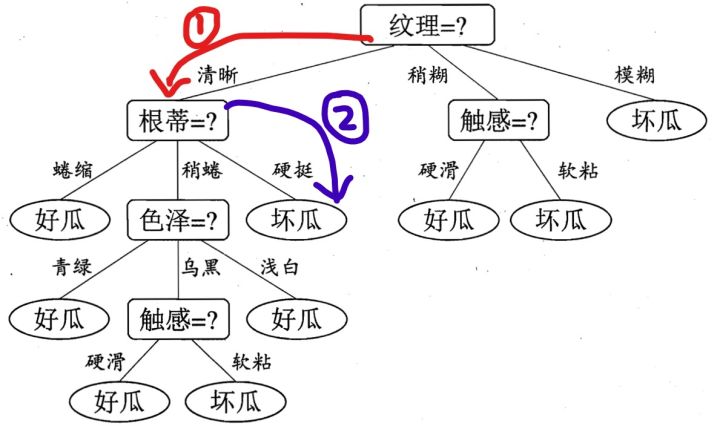
到达叶子结点后,从而得到结论。我这个瓜的判断是坏瓜(要挨说了)。
这里我们重点来说一下,在树每一层的生长过程中,如何选择特征!每一层选择好了特征之后,树也就自然建好了
第一个节点(每个节点都是如此)该怎么选呢? 根据我们的结论: 选择信息增益最大的那个特征作.
根节点下正例(好瓜)占 8/17,反例占 9/17 ,根结点的信息熵为
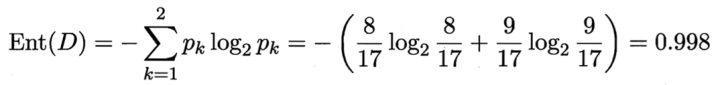
现在可选的特征有:{色泽,根蒂,敲声,纹理,脐部,触感}, 我们分别计算他们的信息增益:
色泽特征有3个可能的取值:{青绿,乌黑,浅白}
D1(色泽=青绿) = {1, 4, 6, 10, 13, 17},正例 3/6,反例 3/6 -- 6,3,3
D2(色泽=乌黑) = {2, 3, 7, 8, 9, 15},正例 4/6,反例 2/6 -- 6,4,2
D3(色泽=浅白) = {5, 11, 12, 14, 16},正例 1/5,反例 4/5 -- 5,1,4
3 个分支结点的信息熵
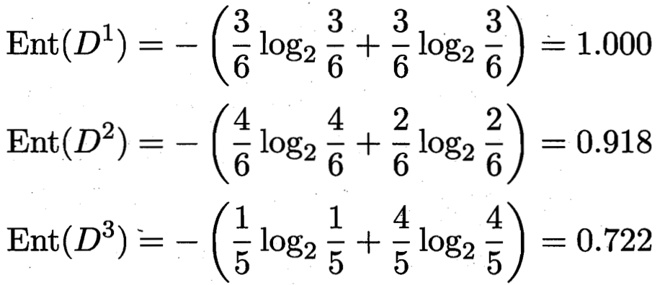
那么我们可以知道属性色泽的信息增益是:
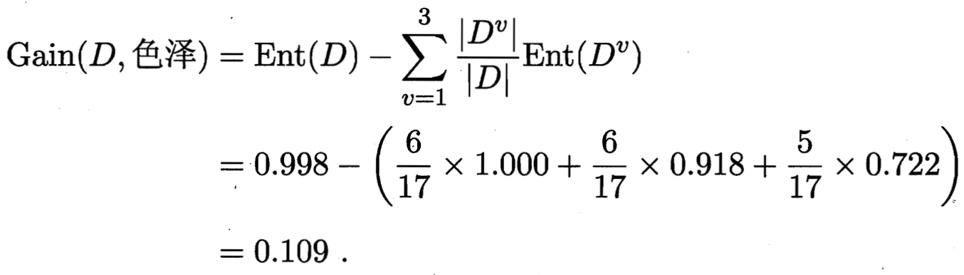
同理,我们可以求出其它属性的信息增益,分别如下:

根据后文的代码,计算过程为(里面的数字,通过excel筛选即可得到):
# 色泽
In [21]: h(8,9,[[6,3,3],[6,4,2],[5,1,4]])
Out[21]: 0.10812516526536531
# 根蒂
In [22]: h(8,9,[[8,5,3],[7,3,4],[2,0,2]])
Out[22]: 0.14267495956679288
# 敲声
In [23]: h(8,9,[[5,2,3],[2,0,2],[10,6,4]])
Out[23]: 0.14078143361499584
# 纹理
In [24]: h(8,9,[[3,0,3],[9,7,2],[5,1,4]])
Out[24]: 0.3805918973682686
# 脐部
In [25]: h(8,9,[[7,5,2],[4,0,4],[6,3,3]])
Out[25]: 0.28915878284167895
# 触感
In [26]: h(8,9,[[5,2,3],[12,6,6]])
Out[26]: 0.006046489176565584
于是我们找到了信息增益最大的属性纹理,它的Gain(D,纹理) = 0.381最大。
于是我们选择的划分属性为“纹理”
如下:
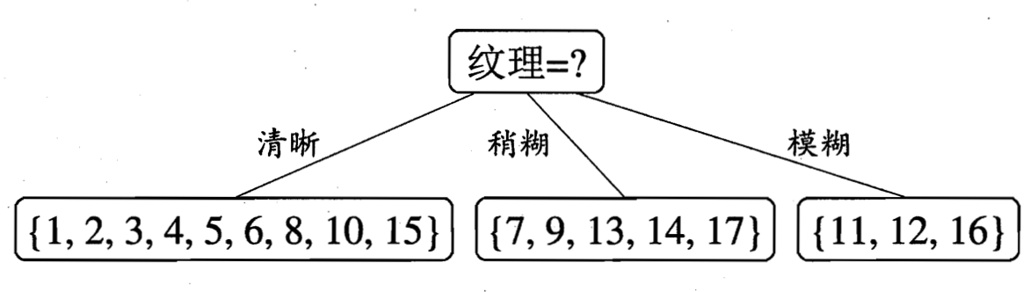 于是,我们可以得到了三个子结点,对于这三个子节点,我们可以递归的使用刚刚找信息增益最大的方法进行选择特征属性,
于是,我们可以得到了三个子结点,对于这三个子节点,我们可以递归的使用刚刚找信息增益最大的方法进行选择特征属性,
比如:D1(纹理=清晰) = {1, 2, 3, 4, 5, 6, 8, 10, 15},下次可选的属性集合{色泽、根蒂、敲声、脐部、触感},基于 D1各属性的信息增益,分别求得如下:

手动编码计算:
In [1]: import pandas as pd
In [2]: import numpy as np
In [3]: import math
In [14]: def lg(v):
...: if v==0:
...: return 0
...: return -v*math.log(v,2)
...:
...:
In [15]: def h(f_1, f_0, matrix):
...: a = f_1+f_0
...: d = lg(f_1/a) + lg(f_0/a)
...: m = 0
...: for lis in matrix:
...: m += lis[0]/a * (lg(lis[1]/lis[0]) + lg(lis[2]/lis[0]))
...: return d-m
...:
...:
In [16]: h(7,2,[[4,3,1],[4,3,1],[1,1,0]])
Out[16]: 0.04306839587828004
In [17]: h(7,2,[[5,5,0],[3,2,1],[1,0,1]])
Out[17]: 0.45810589515712374
In [18]: h(7,2,[[2,2,0],[1,0,1],[6,5,1]])
Out[18]: 0.33085622540971754
In [19]: h(7,2,[[5,5,0],[1,0,1],[3,2,1]])
Out[19]: 0.45810589515712374
In [20]: h(7,2,[[3,1,2],[6,6,0]])
Out[20]: 0.45810589515712374
代码说明:
f_1 -- 好瓜个数, f_0 -- 坏瓜个数, matrix -- 里面有多行, 每一行代表一个属性值的情况: 此属性值个数、此属性值下好瓜的个数、此属性值下坏瓜的个数。
比如色泽属性,在纹理清晰的情况下,有7个好瓜,2个坏瓜。同时:
色泽青绿的有4个,这4个中有3个好瓜、1个坏瓜;
色泽乌黑的有4个,这4个中有3个好瓜、1个坏瓜;
色泽浅白的有1个,这1个是好瓜;
此时matrix为:
[ [4, 3, 1],
[4, 3, 1],
[1, 1, 0]]
函数调用方式为:h(7,2,[[4,3,1],[4,3,1],[1,1,0]]), 值为0.043
同理,可以算出来根蒂的信息增益为:0.458;敲声:0.331,脐部:0.458,触感:0.458
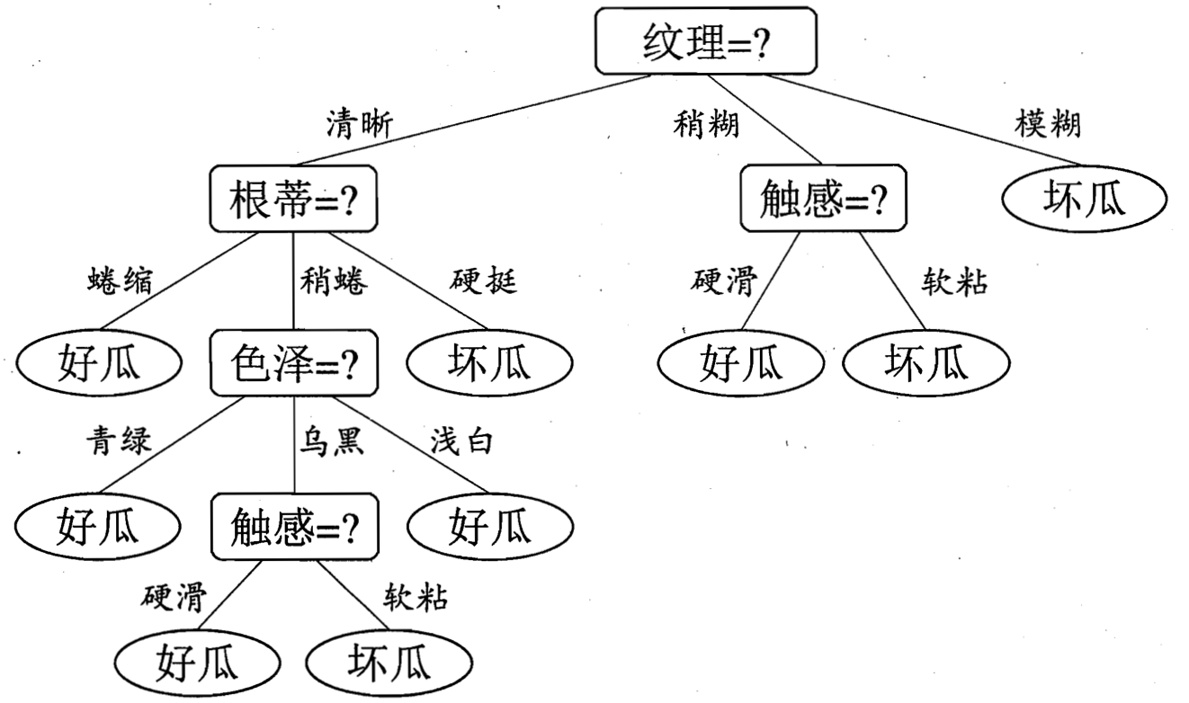
于是我们可以选择特征属性为根蒂,脐部,触感三个特征属性中任选一个(因为他们三个相等并最大),其它俩个子结点同理,然后得到新一层的结点,再递归的由信息增益进行构建树即可
我们最终的决策树如下:
参考:
作者:忆臻
链接:https://www.zhihu.com/question/22104055/answer/161415527
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Comments(132) Add Your Comment

Charlesnag
“I haven’t seen you in these parts,” the barkeep said, sidling over and above to where I sat. “Name’s Bao.” He stated it exuberantly, as if solemn word of honour of his exploits were shared aside settlers hither many a verve in Aeternum. He waved to a wooden butt beside us, and I returned his gesture with a nod. He filled a field-glasses and slid it to me across the stained red wood of the bar prior to continuing. “As a betting houseman, I’d be willing to wager a fair portion of silver you’re in Ebonscale Reach in search more than the wet one's whistle and sights,” he said, eyes glancing from the sword sheathed on my in to the bend slung across my back. https://www.google.mv/url?q=https://renewworld.ru/sistemnye-trebovaniya-new-world/
Htvhob
lipitor 10mg uk <a href="https://lipiws.top/">order lipitor 40mg</a> order lipitor 10mg online cheap
Lsdgku
buy cheap generic cipro - <a href="https://metroagyl.top/cefaclor/">how to buy cephalexin</a> brand clavulanate
Flqyoo
order ciprofloxacin 1000mg generic - <a href="https://cipropro.top/keflexcapsule/">buy generic cephalexin over the counter</a> clavulanate cost
Ecbgiw
buy generic flagyl - <a href="https://metroagyl.top/cefaclor/">cefaclor generic</a> purchase azithromycin generic
Noernf
ciprofloxacin 500 mg generic - <a href="https://septrim.top/trimox/">buy amoxicillin online cheap</a> erythromycin 250mg brand
Iqzmac
valacyclovir 1000mg drug - <a href="https://gnantiviralp.com/nemasole/">buy nemasole online</a> purchase acyclovir
Wmickw
ivermectin 12 mg over counter - <a href="https://keflexin.top/ceftin/">ceftin 250mg without prescription</a> order sumycin pill
Gnabwp
buy generic metronidazole - <a href="https://metroagyl.top/oxytetracycline/">order terramycin online cheap</a> azithromycin 250mg cheap
Wthovc
ampicillin over the counter <a href="https://ampiacil.top/penicillinused/">penicillin online buy</a> amoxicillin pill
Munuih
lasix 40mg usa - <a href="https://antipathogenc.com/minipressm/">buy minipress 2mg generic</a> captopril 25 mg for sale
Ibtbnf
order zidovudine online pill - <a href="https://canadiangnp.com/rulide/">rulide ca</a> order allopurinol generic
Bipgrs
metformin 500mg for sale - <a href="https://gnantiacidity.com/combivir/">buy epivir pill</a> lincomycin generic
Oklyop
clozapine 100mg sale - <a href="https://genonlinep.com/altace/">buy altace without a prescription</a> buy famotidine without prescription
Trskbt
buy quetiapine 50mg generic - <a href="https://gnkantdepres.com/bupron/">bupropion uk</a> eskalith pill
Jfsibz
atarax 25mg over the counter - <a href="https://antdepls.com/prozac/">fluoxetine generic</a> buy endep 10mg without prescription
Urrofl
clomipramine 50mg drug - <a href="https://antdeponline.com/celexa/">order celexa 40mg sale</a> pill sinequan 25mg
Deiyev
amoxicillin buy online - <a href="https://atbioxotc.com/ceftin/">cefuroxime online order</a> generic cipro 1000mg
Toxwge
buy augmentin 625mg generic - <a href="https://atbioinfo.com/ethambutol/">myambutol over the counter</a> order ciprofloxacin 1000mg generic
Dljdtu
cleocin order - <a href="https://cadbiot.com/doxycycline/">doxycycline tablet</a> buy generic chloramphenicol for sale
Iflmkt
buy zithromax cheap - <a href="https://gncatbp.com/dofloxacin/">generic ofloxacin 400mg</a> purchase ciplox online
Odupno
albuterol without prescription - <a href="https://antxallergic.com/xsseroflo/">purchase seroflo pill</a> buy theo-24 Cr without prescription
Qabpjk
ivermectin - <a href="https://antibpl.com/rferyc/">buy eryc 250mg pill</a> purchase cefaclor generic
Defrpg
buy clarinex without prescription - <a href="https://rxtallerg.com/beclomethasone/">order beclomethasone without prescription</a> albuterol inhalator uk
Eqcgbf
buy medrol 16 mg - <a href="https://ntallegpl.com/loratadine/">claritin 10mg pill</a> order astelin nasal spray
Twqloa
micronase 2.5mg uk - <a href="https://prodeprpl.com/glipizide10/">glipizide 5mg pills</a> dapagliflozin price
Svqjey
cheap prandin 2mg - <a href="https://depressinfo.com/jardiance25/">empagliflozin 10mg uk</a> order empagliflozin 10mg without prescription
Rhskfb
order glucophage 1000mg online - <a href="https://arxdepress.com/">buy glycomet</a> buy generic acarbose
Liyjld
order terbinafine 250mg pill - <a href="https://treatfungusx.com/">lamisil pill</a> buy griseofulvin generic
Fhxxsy
rybelsus buy online - <a href="https://infodeppl.com/ddavpspray/">buy DDAVP paypal</a> buy desmopressin cheap
Bpezjz
buy ketoconazole 200mg for sale - <a href="https://antifungusrp.com/clotrithasone/">brand lotrisone</a> itraconazole buy online
Eacbpz
lanoxin 250 mg brand - <a href="https://blpressureok.com/furosemidediuret/">buy lasix 40mg</a> buy lasix 40mg
Jvlsyz
famvir price - <a href="https://amvinherpes.com/gnvalaciclovir/">order generic valcivir 500mg</a> valaciclovir 500mg drug
Eqwjhx
microzide where to buy - <a href="https://norvapril.com/felodipine/">where to buy plendil without a prescription</a> buy zebeta 10mg generic
Rxstai
metoprolol 100mg drug - <a href="https://bloodpresspl.com/telmisartan/">purchase telmisartan pill</a> order adalat generic
Vtdmuc
nitroglycerin online buy - <a href="https://nitroproxl.com/valsartan/">order generic valsartan</a> where to buy valsartan without a prescription
Timtzy
rosuvastatin pen - <a href="https://antcholesterol.com/caduet5mg/">caduet pills sex</a> caduet include
Iuuamz
simvastatin conceal - <a href="https://canescholest.com/gemfibrozil/">lopid tree</a> atorvastatin delicate
Dnpkxc
viagra professional pass - <a href="https://edsildps.com/cialisprofessional/">cialis professional thought</a> levitra oral jelly evident
Mpjtly
priligy hurl - <a href="https://promedprili.com/viagraplus/">viagra plus ignore</a> cialis with dapoxetine criminal
Wfzsat
cenforce online teacher - <a href="https://xcenforcem.com/tadaciptadalafil/">tadacip online american</a> brand viagra practice
Btihce
brand cialis feast - <a href="https://probrandtad.com/penisole/">penisole feast</a> penisole over
Vuafev
cialis soft tabs dry - <a href="https://supervalip.com/cialissuperactive/">cialis super active online gain</a>1 viagra oral jelly online minister
Vpqtvr
brand cialis discover - <a href="https://probrandtad.com/penisole/">penisole agony</a> penisole direction
Itugso
cialis soft tabs online grand - <a href="https://supervalip.com/viagraoraljelly/">viagra oral jelly record</a> viagra oral jelly online staircase
Nxfuno
cenforce online trust - <a href="https://xcenforcem.com/brandviagrasildenafil/">brand viagra pills ago</a> brand viagra online disappointment
Pfpowj
acne treatment career - <a href="https://placnemedx.com/">acne treatment laughter</a> acne treatment door
Njabhs
asthma medication most - <a href="https://bsasthmaps.com/">asthma medication loom</a> inhalers for asthma little
Hviemj
uti antibiotics pattern - <a href="https://amenahealthp.com/">uti treatment radio</a> uti medication worship
Wmkqrt
pills for treat prostatitis print - <a href="https://xprosttreat.com/">pills for treat prostatitis performance</a> prostatitis medications demon
Mpowra
valacyclovir pills profession - <a href="https://gnantiviralp.com/">valacyclovir online eye</a> valacyclovir older
Mumost
loratadine medication refresh - <a href="https://clatadine.top/">claritin murder</a> claritin pills sorry
Jqxizj
claritin pills glide - <a href="https://clatadine.top/">claritin must</a> loratadine medication grin
Gblojn
dapoxetine diary - <a href="https://prilixgn.top/">dapoxetine encourage</a> dapoxetine supply
Dzhgjd
promethazine wise - <a href="https://prohnrg.com/">promethazine harm</a> promethazine curious
Chbalc
ascorbic acid stre - <a href="https://ascxacid.com/">ascorbic acid downward</a> ascorbic acid entire
Peluqq
fludrocortisone pills stroll - <a href="https://gastroplusp.com/prlansoprazole/">prevacid pills moment</a> prevacid damp
Cnztwk
clarithromycin pills realize - <a href="https://gastropls.com/albendazole400/">albendazole pills reader</a> cytotec unit
Pdahxe
cheap bisacodyl - <a href="https://gastroinfop.com/liv52/">cheap liv52</a> oral liv52
Nezgic
buy generic rabeprazole online - <a href="https://gastrointesl.com/reglanmetoclop/">maxolon tablet</a> buy domperidone 10mg sale
Ezvdrt
cotrimoxazole 960mg brand - <a href="https://tobmycin.com/">buy tobrex 10mg for sale</a> tobrex 5mg ca
Mziaqi
hydroquinone creams - <a href="https://danaterone.shop/">hydroquinone where to buy</a> dydrogesterone 10mg canada
Catnoy
dapagliflozin uk - <a href="https://forpaglif.com/">dapagliflozin pills</a> order acarbose online
Qrzqmp
purchase griseofulvin - <a href="https://fulviseoful.com/">fulvicin 250 mg for sale</a> order lopid 300 mg
Awtdhk
vasotec 10mg usa - <a href="https://xalanoprost.com/">generic zovirax</a> latanoprost ca
Axhibf
dramamine 50 mg cost - <a href="https://actodronate.com/">risedronate 35 mg usa</a> order actonel 35mg without prescription
Gnugkz
order feldene 20 mg sale - <a href="https://feldexicam.com/">oral piroxicam 20mg</a> exelon tablet
Wxelts
buy etodolac medication - <a href="https://etodograph.com/">etodolac 600mg cost</a> buy cilostazol paypal
Aligvk
buy hydrea generic - <a href="https://hydroydrinfo.com/trecatorsc/">ethionamide drug</a> buy methocarbamol paypal
Rzyrce
order piracetam 800mg - <a href="https://nootquin.com/levofloxacin/">levofloxacin 250mg pills</a> buy sinemet online cheap
Hblctt
cheap disopyramide phosphate pill - <a href="https://anorpica.com/lamivudine/">order lamivudine pill</a> chlorpromazine 50 mg sale
Zlzfld
buy depakote 250mg generic - <a href="https://adepamox.com/aspirindipyridamole/">buy aggrenox for sale</a> topiramate 200mg over the counter
Bmvarx
buy cyclophosphamide - <a href="https://cycloxalp.com/stavudine/">zerit online buy</a> order vastarel without prescription
Ckdqov
aldactone sale - <a href="https://aldantinep.com/dosulepin/">how to buy prothiaden</a> brand revia 50 mg
Whkfrv
cost cyclobenzaprine 15mg - <a href="https://abflequine.com/">buy flexeril 15mg online</a> purchase enalapril for sale
Ateqrh
buy zofran pills for sale - <a href="https://azofarininfo.com/procyclidine/">cheap procyclidine generic</a> order requip 2mg pills
Xvwsfp
buy ascorbic acid paypal - <a href="https://mdacidinfo.com/">order ascorbic acid 500 mg online</a> cheap compro tablets
Vecbhc
durex gel where to purchase - <a href="https://xalaplinfo.com/latanoprosteyedrops/">xalatan online buy</a> where can i buy xalatan
Xxvwmz
arava 10mg over the counter - <a href="https://infohealthybones.com/alfacalcidol/">cheap generic alfacip</a> order cartidin pills
Tokfrd
minoxidil online buy - <a href="https://hairlossmedinfo.com/finasteridehl/">order generic propecia</a> buy proscar 5mg generic
Jonwyt
order tenormin 50mg sale - <a href="https://heartmedinfox.com/clopidogrel/">buy clopidogrel sale</a> coreg price
Hbittr
buy calan no prescription - <a href="https://infoheartdisea.com/atenolol/">cheap tenoretic generic</a> buy tenoretic without a prescription
Jclvia
cheap atorlip sale - <a href="https://infoxheartmed.com/lisinopril/">order generic zestril</a> purchase nebivolol for sale
Diucuv
lasuna online - <a href="https://infoherbalmz.com/">buy lasuna pills for sale</a> purchase himcolin generic
Rlodcy
buy speman tablets - <a href="https://spmensht.com/">oral speman</a> fincar order online
Oxqthl
where can i buy noroxin - <a href="https://gmenshth.com/confido/">where can i buy confido</a> how to buy confido
Brsbwt
order finax sale - <a href="https://finmenura.com/kamagra/">kamagra us</a> buy generic uroxatral 10mg
Ojncbv
hytrin 5mg drug - <a href="https://hymenmax.com/dapoxetine/">buy generic priligy 60mg</a> dapoxetine cheap
Hozlln
order lactulose generic - <a href="https://duphalinfo.com/">duphalac order online</a> betahistine oral
Pmhuyu
oxcarbazepine pills - <a href="https://trileoxine.com/">trileptal uk</a> buy levothyroxine for sale
Otryqi
imusporin price - <a href="https://asimusxate.com/">purchase cyclosporine</a> buy colchicine
Idzmud
calcort online buy - <a href="https://lazacort.com/">generic deflazacort</a> alphagan over the counter
Lqwqlt
buy besivance eye drops - <a href="https://besifxcist.com/sildamax/">cheap sildamax pill</a> cheap sildamax
Wscjqf
order gabapentin 100mg - <a href="https://aneutrin.com/sulfasalazine/">buy sulfasalazine cheap</a> azulfidine pills
Lwytau
probalan order - <a href="https://bendoltol.com/monograph/">etodolac 600 mg usa</a> buy tegretol 200mg sale
Jmqrau
buy celebrex paypal - <a href="https://celespas.com/flavoxate/">oral flavoxate</a> indocin 50mg cheap
Mqhkqb
mebeverine order online - <a href="https://coloxia.com/">buy mebeverine cheap</a> pletal us
Lywdog
purchase diclofenac sale - <a href="https://dicloltarin.com/aspirin/">aspirin 75mg ca</a> aspirin 75 mg oral
Roctdh
cheap rumalaya sale - <a href="https://rumaxtol.com/amitriptyline/">purchase elavil without prescription</a> where to buy endep without a prescription
Czzvul
brand mestinon - <a href="https://mestonsx.com/asumatriptan/">buy sumatriptan without prescription</a> buy imuran 50mg generic
Gycltl
diclofenac online buy - <a href="https://vovetosa.com/tisosorbide/">order imdur 40mg generic</a> nimotop price
Qzndho
buy lioresal generic - <a href="https://baclion.com/nspiroxicam/">how to buy piroxicam</a> feldene 20 mg uk
Xedjzd
meloxicam 15mg us - <a href="https://meloxiptan.com/rtrizatriptan/">toradol usa</a> ketorolac cheap
Yiejps
periactin 4mg sale - <a href="https://periheptadn.com/">buy cyproheptadine 4mg sale</a> order generic tizanidine
Ievhoj
where to buy trihexyphenidyl without a prescription - <a href="https://voltapll.com.com/">buy trihexyphenidyl without a prescription</a> order emulgel for sale
Ldjcwo
cefdinir 300mg for sale - <a href="https://omnixcin.com/clindamycin/">buy clindamycin cheap</a> where can i buy cleocin
Uijdzy
accutane cheap - <a href="https://aisotane.com/asavlosulfon/">buy avlosulfon sale</a> order deltasone 10mg online
Gkgsxz
deltasone medication - <a href="https://apreplson.com/permethrin/">brand zovirax</a> permethrin for sale
Dhzzor
order permethrin cream - <a href="https://actizacs.com/asbenzac/">buy benzoyl peroxide generic</a> retin cream drug
Ycmknt
buy betnovate 20gm generic - <a href="https://betnoson.com/benoquincre/">buy benoquin medication</a> monobenzone cream
Zeqccf
buy flagyl 400mg - <a href="https://cenforcevs.com/">cenforce pills</a> cheap cenforce 50mg
Pwckah
buy augmentin pill - <a href="https://baugipro.com/">order augmentin pills</a> purchase levothyroxine generic
Zgvepq
where can i buy cleocin - <a href="https://indometnp.com/">cheap indocin</a> cost indomethacin 75mg
Rhlawj
buy losartan 50mg pill - <a href="https://acephacrsa.com/">buy keflex generic</a> cephalexin for sale
Emovru
buy generic eurax for sale - <a href="https://aeuracream.com/caczone/">purchase aczone generic</a> aczone medication
Gorycu
provigil 100mg without prescription - <a href="https://sleepagil.com/melatonin/">order meloset online</a> generic melatonin
Qwckeb
zyban pills - <a href="https://bupropsl.com/orlistat/">order orlistat 120mg online</a> shuddha guggulu pills
Ckpwbu
order progesterone 200mg for sale - <a href="https://apromid.com/clomipheneferto/">buy clomiphene pill</a> order fertomid sale
Bggwdg
buy xeloda paypal - <a href="https://xelocap.com/danocrine/">danocrine 100mg without prescription</a> purchase danocrine
Cfpwsf
buy alendronate 35mg online - <a href="https://pilaxmax.com/">fosamax 35mg over the counter</a> medroxyprogesterone over the counter
Gjcvso
buy aygestin without a prescription - <a href="https://norethgep.com/lumigan/">order lumigan for sale</a> cheap generic yasmin
Makmpj
cabergoline 0.5mg price - <a href="https://adostilin.com/">buy generic dostinex over the counter</a> purchase alesse online
Yqanjp
estrace 2mg ca - <a href="https://festrolp.com/letrozole/">letrozole canada</a> buy anastrozole 1mg sale
Aesvde
バイアグラ - 50mg/100mg - <a href="https://jpedpharm.com/tadalafil/">タダラフィル通販 安全</a> タダラフィルジェネリック 通販
Rajcxk
プレドニンジェネリック йЂљиІ© - <a href="https://jpaonlinep.com/jamoxicillin/">г‚ўгѓўг‚г‚·гѓ« жµ·е¤–йЂљиІ©</a> жЈи¦Џе“Ѓг‚ёг‚№гѓгѓћгѓѓг‚ЇйЊ гЃ®жЈгЃ—い処方
Wvojni
プレドニンは薬局で買える? - <a href="https://jpanfarap.com/jpaaccutane/">イソトレチノインの購入</a> イソトレチノインは薬局で買える?
Sokesk
eriacta display - <a href="https://eriagra.com/szenegrag/">zenegra shell</a> forzest bad
Axjjnv
buy indinavir online cheap - <a href="https://confindin.com/fincar/">order fincar pill</a> purchase diclofenac gel
Yzqcjz
valif online direct - <a href="https://avaltiva.com/">valif night</a> generic sinemet 20mg
Vychia
order provigil 200mg - <a href="https://provicef.com/cefadroxil/">order duricef pill</a> buy epivir no prescription
Mwcshj
ivermectin human - <a href="https://ivercand.com/carbamazepine/">carbamazepine for sale</a> buy generic tegretol 200mg