django项目开发流程
2024-11-02 13:02:00 by wst
django概述
总体来说,开发包含两大过程:整理思路、编码。
整理思路我们可以借助流程图,相关的工具有
- Draw.io vscode中也有相关插件(推荐)。
- ProcessOn
- Zen Flowchart
整理思路和具体业务相关,这里着重介绍编码过程。
创建项目
正常情况下,项目都是提前创建好的。如果是一个从0到1的项目,创建过程如下:
# 创建项目
django-admin startproject DemoProject
# 创建应用
cd DemoProject
python manage.py startapp book
然后是对应用做一些配置。
1. 添加新建立的应用的到配置文件中,修改DemoProject/settings.py, 添加book到INSTALLED_APPS:
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'book.apps.BookConfig'
]
2.添加路由配置,包括book/views.py、book/urls.py(需要新建)、DemoProject/urls.py,内容如下:
# book/views.py
from django.http.response import HttpResponse
def index(request):
return HttpResponse("欢迎来到book应用!")
# book/urls.py
from book.views import index
from django.urls import path
urlpatterns = [
path('index', index),
]
# DemoProject/urls.py
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('book/', include('book.urls')),
path('admin/', admin.site.urls),
]
3.后续其他配置,如:创建model、迁移数据库,非本文档核心这里不赘述。
开发项目
常规情况下,项目的框架、model是创建好的,我们需要做的是的利用DRF实现逻辑。
1实现逻辑
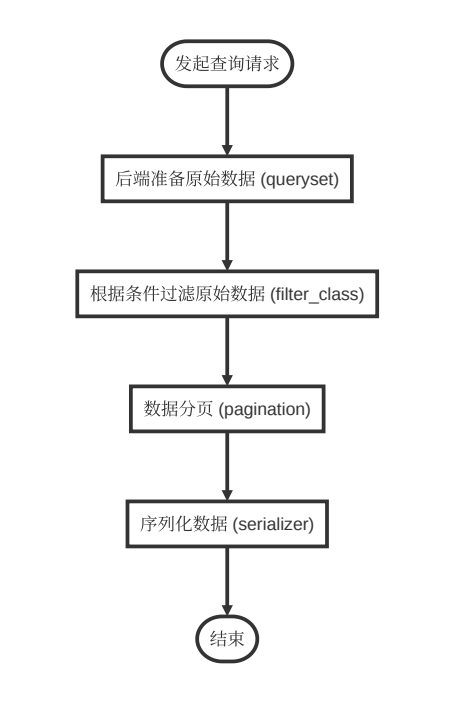
1.1查询
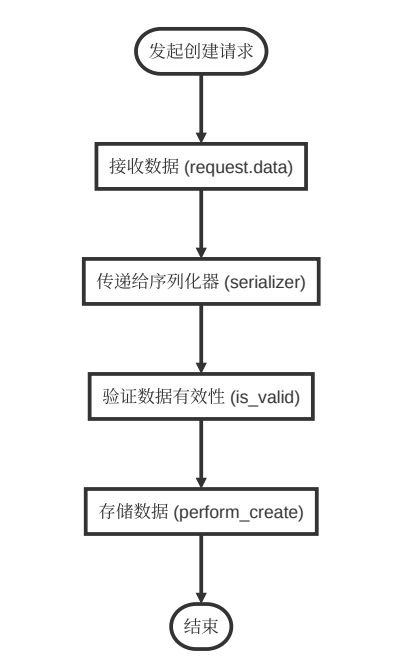
1.2创建
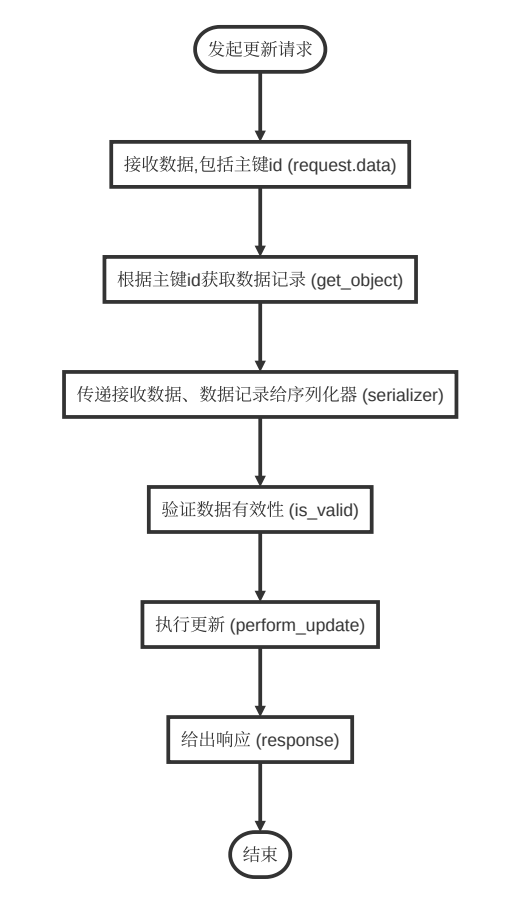
1.3更新
2编码实例
逻辑说明:这里要查询某个公司自己的月账单,查询条件包括开始月份、结束月份。
思路:从数据库里初筛本公司的月账单,然后利用过滤器过滤月份,然后分页,然后传给序列化器,生成前端需要的数据形式。
2.1获取初始数据集
关注get_queryset函数,可以确定的是:要查本公司的账单。
from rest_framework.generics import ListAPIView
from client.filters.bill import MonthBillFilter
from client.serializers.bill import MonthBillSerializer
from utils.drf.paginations import MyPageNumberPagination
class MonthBillView(ListAPIView):
filter_class = MonthBillFilter
serializer_class = MonthBillSerializer
pagination_class = MyPageNumberPagination
def get_queryset(self):
return HistoryMonthBill.objects.filter(
company=self.request.company,
).order_by('-month')
2.2根据条件过滤数据
from django_filters import rest_framework as filters
from client.models.data_summary import HistoryMonthBill
class MonthBillFilter(filters.FilterSet):
start_month = filters.DateFilter(field_name="month", lookup_expr="gte")
end_month = filters.DateFilter(field_name="month", lookup_expr="lte")
class Meta:
model = HistoryMonthBill
fields = ["start_month", "end_month"]
2.3数据分页
from collections import OrderedDict
from rest_framework.response import Response
from rest_framework.pagination import PageNumberPagination
class MyPageNumberPagination(PageNumberPagination):
"""
指定页码和显示数量分页
"""
# 默认每页显示数量
page_size = 20
# url中每页显示条数的参数
page_size_query_param = 'size'
# url中页码的参数
page_query_param = 'page'
# 每页最多显示多少条
max_page_size = 50
def get_paginated_response(self, data):
"""
重写返回结果
:param data:
:return:
"""
return Response(OrderedDict([
('total', self.page.paginator.count),
('current_page', self.page.number),
('page_range', list(self.page.paginator.page_range)),
('list', data)
]))
2.4序列化数据
序列化的目的是,把库里的数据变成前端可用的形式(json)。
from rest_framework import serializers
from client.models.data_summary import HistoryMonthBill
class MonthBillSerializer(serializers.ModelSerializer):
month = serializers.SerializerMethodField(label="对账月份")
count = serializers.IntegerField(label="单月数据条数", source="record_count")
def get_month(self, val):
return val.month.strftime("%Y-%m")
class Meta:
model = HistoryMonthBill
fields = ['id', 'month', 'count']
2.5总结
一般我们先写好视图类(MonthBillView)的框架 和 get_queryset函数,然后定义序列化器(MonthBillSerializer),然后定义过滤器(MonthBillFilter),然后定义分页器(MyPageNumberPagination)。最后把他们配置到视图类中。
3DRF框架说明
3.1视图基类的选择
- 如果为列表数据,则选择
ListAPIView; - 如果为创建请求,则选择
CreateAPIView - 其他,如:列表和创建
ListCreateAPIView,单条记录查询RetrieveAPIView,删除记录DestroyAPIView,等等。
3.2序列化字段的特殊情况
1添加额外字段: 添加一个total_likes点赞总数的字段,只需要在序列化器类里重写to_representation方法。或者使用序列化方法获得文章字数。
from rest_framework import serializers
from .models import Article
class ArticleSerializer(serializers.ModelSerializer):
word_count = serializers.SerializerMethodField(label="文章字数")
def get_word_count(self, val):
return len(val.content)
class Meta:
model = Article
fields = '__all__'
def to_representation(self, value):
# 调用父类获取当前序列化数据,value代表每个对象实例ob
data = super().to_representation(value)
# 对序列化数据做修改,添加新的数据
data['total_likes'] = value.liked_by.count()
return data
2嵌套序列化器
用途:文章中的author字段实际上对应的是一个User模型实例化后的对象,既不是一个整数id,也不是用户名这样一个简单字符串,这里需要显示更多用户信息。
class UserSerializer(serializers.ModelSerializer):
class Meta:
model = User
fields = ('id', 'username', 'email')
class ArticleSerializer(serializers.ModelSerializer):
# author = UserSerializer(read_only=True)
author = UserSerializer() # required=False表示可接受匿名用户,many=True表示有多个用户。
status = serializers.ReadOnlyField(source="get_status_display")
cn_status = serializers.SerializerMethodField()
class Meta:
model = Article
fields = '__all__'
read_only_fields = ('id', 'author', 'create_date')
def get_cn_status(self, obj):
if obj.status == 'p':
return "已发表"
elif obj.status == 'd':
return "草稿"
else:
return ''
3.3过滤器的特殊情况
通过函数过滤某个字段(status),实例如下:
class OpenApprovalFilter(filters.FilterSet):
""" 开立审批 根据查询条件过滤数据 """
number = filters.CharFilter(field_name='number', lookup_expr='icontains')
status = filters.CharFilter(method='filter_status')
company_name = filters.CharFilter(field_name='company__name', lookup_expr='icontains')
open_start_date = filters.DateFilter(field_name='created_at', lookup_expr="gte")
open_end_date = filters.DateFilter(field_name='created_at', lookup_expr="lte")
pay_start_date = filters.DateFilter(field_name='promise_pay_at', lookup_expr="gte")
pay_end_date = filters.DateFilter(field_name='promise_pay_at', lookup_expr="lte")
def filter_status(self, queryset, name, value):
"""
检查状态是否合法
"""
if value not in ('undo', 'done'):
raise (APIException("状态参数status不合法!"))
return queryset
class Meta:
model = CreditCertificate
fields = ["number", "status", "company_name", "open_start_date", "open_end_date",
"pay_start_date", "pay_end_date"]